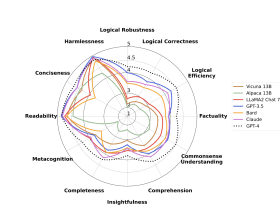
A New AI Research from KAIST Introduces FLASK: A Fine-Grained Evaluation Framework for Language Models Based on Skill Sets
CRANK
Incredibly, LLMs have proven to match with human values, providing helpful, honest, and harmless responses. In particular, this capability has been greatly enhanced by methods that fine-tune a pretrained LLM on various tasks or user preferences, such as instruction tuning and reinforcement learning from human feedback (RLHF). Recent research suggests that by evaluating models solely based on binary human/machine choice, open-sourced models trained via dataset distillation from proprietary models can close the performance gap with the proprietary LLMs. Researchers in natural language processing (NLP) have proposed a new evaluation protocol called FLASK (Fine-grained Language Model Evaluation based on Alignment Skill